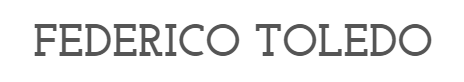
Puede ser un poco “overwhelming” pensar en todas las tareas de testing que tenemos para hacer. Podemos mirar por ejemplo lo que alguna vez escribí por acá: The Software Testing Wheel. Luego de hacer un brainstorming, o incluso la dinámica de estrategia de testing como la propuesta acá, aparece una enormidad de “cosas que sería interesante probar”. Ahí hay que empezar a aplicar Pareto: ¿cuál es ese 20% de cosas que podemos probar que nos van a dar el 80% del valor? (viendo la siguiente imagen, una foto que tomé en la conferencia CMG imPACt el año pasado, queda muy clara la representación de esta famosa ley). O dicho de otra forma, tomar un enfoque basado en riesgos, apuntando a seleccionar las tareas que nos permiten mitigar primero los aspectos de mayor riesgo. En este post quiero resumir una dinámica que plantea hacer ese análisis utilizando una matriz de riesgo para testing.
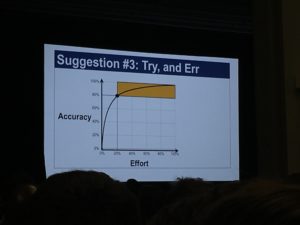
Matriz de Riesgo
El riesgo tiene dos factores: la probabilidad de que algo suceda y el impacto que esto genera si sucede. Entonces, si lo dibujamos en una matriz, vamos a poder distinguir zonas según el riesgo, donde los extremos serán:
- Muy probable y mucho impacto: ¡Lo tenemos que probar!
- Poco probable y mucho impacto: Lo deberíamos probar.
- Muy probable y bajo impacto: Si hay tiempo, lo podríamos probar.
- Poco probable y bajo impacto: Si probamos esto seguramente perdemos plata. O sea, probablemente sea más cara la prueba que el beneficio que obtenemos. Entonces, no se prueba.
Se puede representar por ejemplo como se ve en la imagen:
Esto está asociado al enfoque MoSCoW: Must (High), Should (Medium de alto impacto), Could (Medium de bajo impacto), Wont (Low). En la siguiente imagen se muestra una dinámica hecha para hacer un análisis de riesgo con este método (ojo, no está en el mismo orden que la matriz anterior):

También se puede ir por una versión más refinada de la matriz como se ve en esta imagen:
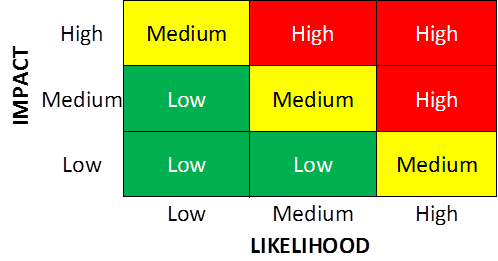
Matriz de Riesgo para Testing
Una dinámica que se puede hacer con la matriz de riesgo para testing es la siguiente:
#1 – Pensar cuáles son los factores que afectan la probabilidad de que aparezca un incidente. Por ejemplo:
- Complejidad de la solución.
- Dependencia de sistemas externos.
#2 – Luego, pensar cuáles son los factores que generan impacto negativo en el negocio, en caso que la funcionalidad tenga problemas:
- Funcionalidades que operan con datos sensibles.
- Funcionalidades muy usadas.
#3 – Luego se puede poner foco en esta técnica de distintas maneras, pensando por ejemplo en las técnicas a aplicar, o en las funcionalidades a probar. Por ejemplo, uno podrá ubicar en los cuadrantes a las distintas funcionalidades, o tal vez, poner “pruebas de seguridad”, “pruebas de performance”, etc. También se podría aplicar para decidir a qué probarle la performance, o a qué probarle la seguridad. O quizá, para definir cuánto tiempo de testing exploratorio dedicarle a cada funcionalidad.
El tablero que hemos usado alguna vez en la dinámica es el siguiente, donde dejamos representados los cuadrantes según riesgo, y también asociándolo a la técnica MoSCoW:
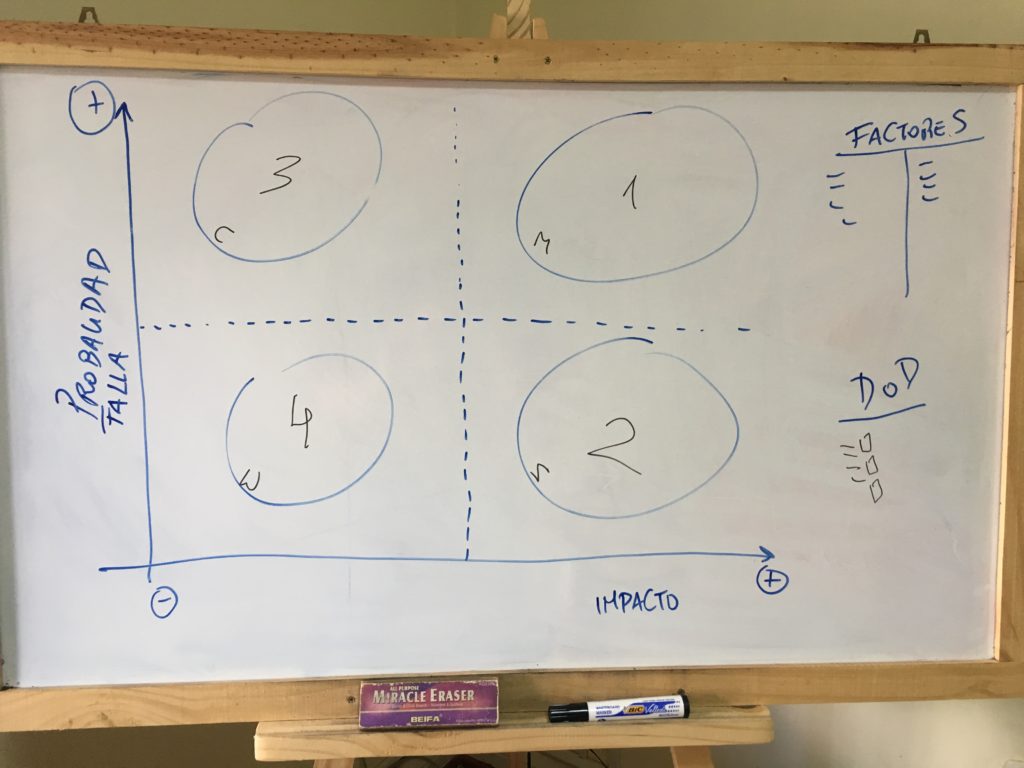
Algo que hemos visto interesante, es que de esta matriz de riesgo se podría llegar a desprender el Definition of Done (DoD), distinguiendo distintos DoD según la criticidad de la historia/funcionalidad. Entonces, para algunas historias definidas como de categoría 3 (Could), se definan ciertos tipos de pruebas, automatización con cierto nivel de cobertura, etc., y luego para otra historia que se categorice como 1 (Must) habrá un DoD distinto, con otras tareas asociadas más exigente en cuanto a los controles de calidad.
Esta técnica puede ser bien útil para una retrospectiva, con foco en tareas de calidad.
Próximamente: taller de técnicas de testing para equipos ágiles
Esto es una de las tantas técnicas que vamos a poner en práctica con Gabriel en el próximo taller de testing ágil que brindaremos. Si te interesa aprender al respecto, informate e inscribite acá.



Muy clara toda la explicación
Muy concreta y clara la explicación para quienes estamos iniciando.
Muchas gracias!