Al hablar de plan de pruebas de performance no me refiero al documento, sino a qué vamos a ejecutar en el tiempo que tenemos destinado a las pruebas, como para que con la menor cantidad de ejecuciones posible seamos capaces de responder las interrogantes de performance por las cuales nos indicaron hacer la prueba.
Entonces, primero que nada es necesario saber qué preguntas vamos a contestar con los resultados de las pruebas. Aquí creo que resumo los ejemplos más comunes:
- Prueba de estrés (stress testing): ¿Cuál es la cantidad máxima de usuarios concurrentes que soporta el sistema con una experiencia de usuario aceptable? O sea, ¿cuál es el punto de quiebre?
- Prueba de carga (load test): Dado el escenario actual de carga del sistema, ¿cómo se comportará la aplicación? ¿qué oportunidades de mejora encuentro para ese escenario esperado?
- Prueba de endurance: ¿Cómo funcionará el sistema luego de estar cierto tiempo ejecutando, digamos luego de estar un día entero en régimen? (en algunos casos esto implicó tomar acciones como la de reiniciar el servidor cada noche hasta encontrar una solución definitiva a algún leak presente en el sistema).
- Prueba de picos: Si mi sistema en régimen normal funciona adecuadamente y viene un pico de estrés (la casuística hace que en un mismo momento coincidan muchas más peticiones que lo normal, ante lo cual sé que los tiempos de respuesta quizá empeoran por debajo de lo aceptable), entonces ¿qué tan rápido se recupera el sistema?
En cualquier caso hay otra pregunta que está siempre presente en toda prueba de performance: ¿cuáles son los cuellos de botella principales? y ¿cómo soluciono los problemas o limitantes con las que me encuentre? Incluso podríamos responder cosas como ¿mi equipo está preparado para cuando algo así pase en producción o necesito aprender algo más? ¿qué disponibilidad de recursos físicos tengo disponibles o cuán difícil es conseguirlos? o ¿qué tan rápido damos soluciones a problemas de performance?
Con esto ya tenemos mucho para trabajar; muchas veces es necesario revisar los access log del sistema para tener una idea de la cantidad de usuarios que se conectan a diario, o tenemos que hacer estimaciones y averiguaciones de cuántos usuarios se esperan recibir. Esto al diseñar la prueba se refina mucho más, ya que es necesario indagar qué hacen cada uno de esos usuarios (qué casos de prueba, con qué datos, etc.). En lo que me quiero centrar en este post es en cómo ejecutar ese escenario de carga.
Plan de pruebas de performance: ¿con cuántos usuarios concurrentes ejecuto las pruebas?
Algo que ya lo he repetido tantas veces que ahora ya debe ser verdad: si diseñamos / definimos nuestro escenario de carga con una cantidad X de usuarios, no podemos comenzar ejecutando una prueba que simule los X usuarios concurrentes de una. Si hacemos eso, seguramente (por experiencia) aparezcan tantos problemas a la vez que no sabremos por dónde comenzar. De ahí es que surge la idea de aplicar una metodología iterativa incremental para nuestro plan de pruebas de performance: iterativa porque se van ejecutando distintas iteraciones de prueba, de manera incremental, comenzando con una cantidad reducida de usuarios concurrentes, solucionando los problemas que se vayan identificando, y avanzando aumentando la concurrencia.
Ejemplo: Prueba de carga
Consideremos como primer ejemplo que estamos haciendo una prueba de carga, donde el objetivo de la prueba es analizar si el sistema soporta 1.000 usuarios concurrentes (aclaración: no estoy teniendo en cuenta el tema de entorno de test, y qué tan similar es al de producción, y cómo definir el alcance en base a la diferencia de los ambientes).
- Primera prueba: 1 usuario sin concurrencia (esto puede servir como baseline, para comparar luego, puede ser con 1, 5, 10 o más, pero tiene que ser algo sumamente reducido para lo esperado en el sistema).
- Segunda prueba: 200 usuarios concurrentes (o sea, el 20% de la carga esperada). Aquí ya se puede obtener muchísima información sobre qué tan difícil la vamos a tener para completar la prueba en tiempo y forma.
Al ejecutar estas primeras pruebas vamos a resolver los problemas más “gruesos”, las configuraciones por defecto (pools de conexión o tamaño del heap de Java por ejemplo), y vamos a tener una idea de cómo escala el sistema comparando los tiempos de respuesta con respecto al baseline. Una vez que se termina el análisis y resolución de problemas, se vuelve a ejecutar esta prueba hasta que se obtengan tiempos aceptables. Según qué tan ajustados sean esos resultados vamos a decidir si la tercera prueba será la del 40% (para seguir con incrementos de a 20) o si vamos con 50% de la carga (pensando en pasar luego al 75 y al 100), o si el sistema responde muy bien, quizá nos animemos a pasar directamente a más. En cualquier caso, lo que queremos tener al final es una gráfica que nos muestre los tiempos de respuesta obtenidos con cada prueba (con cada porcentaje de la carga esperada), y así podremos ver cómo fue evolucionando el sistema gracias a nuestro trabajo.
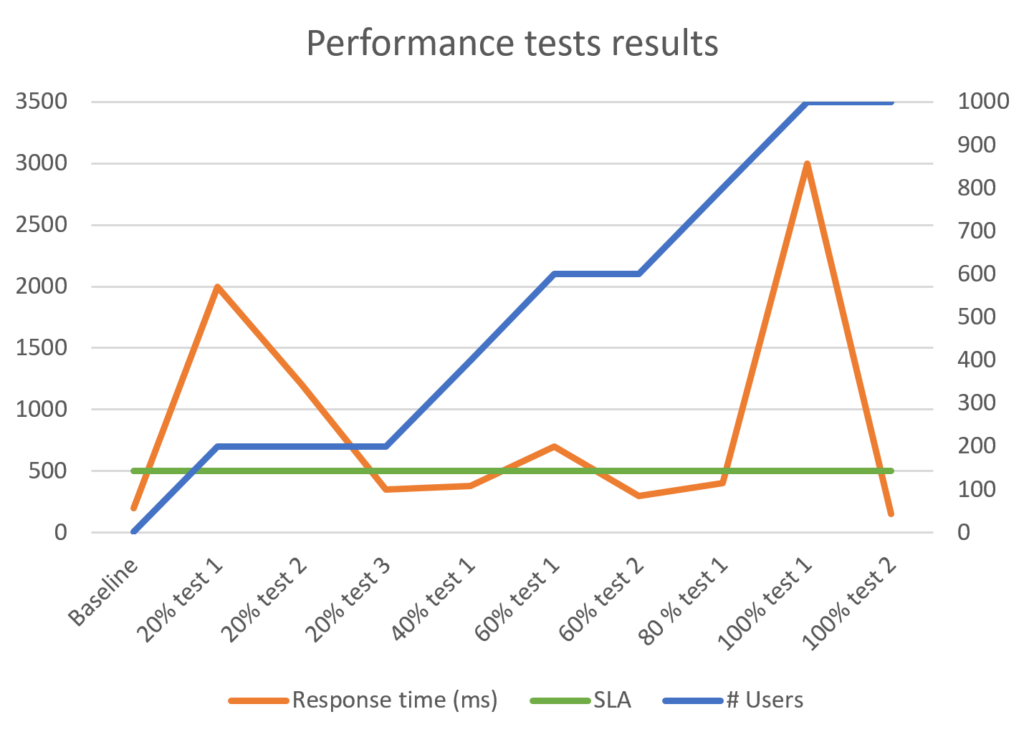
En esta gráfica de ejemplo vemos cómo se ejecutaron distintas pruebas incrementando de a 20% la carga. Además se puede observar fácilmente que se repitieron las pruebas hasta alcanzar el SLA esperado en cada caso, y recién al alcanzarlo se pasó al siguiente escalón.
Ejemplo: Prueba de estrés
Como segundo ejemplo, imaginemos que queremos encontrar el punto de quiebre del sistema con una prueba de estrés. Para eso queremos ejecutar distintas pruebas, con distintas cantidades de usuarios, analizando si al aumentar la concurrencia sigue aumentando el throughput (si al aumentar la concurrencia no aumenta las transacciones por segundo, eso indica que llegamos al punto de quiebre, ya que se está saturando el sistema en algún punto, sin escalar).
Si comenzamos a ejecutar pruebas con números de usuarios al azar, va a ser un tiro al blanco de ojos cerrados y perderemos mucho tiempo. La mejor estrategia considero que es ejecutar una prueba que podríamos llamar prueba exploratoria de performance, ya que la ejecutaríamos para tener una primera idea de dónde está ese punto de quiebre. Para esto, ejecutamos una prueba incremental de 0 a X, donde X es una cantidad de usuarios grande (digamos 1.000 para considerar una generadora de carga sola) y que creemos que el quiebre tiene que estar en ese rango. Lo que se puede hacer en cualquier herramienta de simulación de carga para ejecutar esta prueba es establecer un rampup uniforme durante el tiempo de la prueba. O sea, si queremos que esa prueba dure una hora, configuramos para que la prueba comience con cero usuarios concurrentes, y al cabo de una hora tenga 1.000. Aquí vamos a poder tener una primera aproximación a ver cuándo el throughput del sistema se degrada. Si observamos que es alrededor de los 650 usuarios, ahí podemos comenzar a refinar ejecutando pruebas puntuales. Por ejemplo, podríamos ejecutar una prueba con 500, otra con 600, otra con 700. Si efectivamente la prueba de 700 usuarios tiene menos throughput que la de 600, hay que refinar y ejecutar una con 650, y así seguimos con el punto medio, hasta mejorar la precisión.
Ejemplo: Prueba de endurance
Para una prueba de endurance, diría de ejecutar una carga constante que esté entre el 50 y el 70% de la carga soportada por el sistema en condiciones aceptables. Podría servir una carga menor también, todo dependerá de qué tan complejo sea preparar los datos de prueba para poder ejecutar durante muchas horas.
Por lo general estas pruebas se ejecutan una vez terminadas las pruebas de estrés o carga que se hayan realizado, para intentar identificar otros tipos de problemas (memory leaks, conexiones colgadas, etc.). Si se cuenta con tiempo, datos y lo que se necesite para esto, se podrían incrementar las cargas que se utilicen para las pruebas, ejecutándolas en forma prolongada.
Ejemplo: Prueba de picos
Para una prueba de picos como dijimos antes, la idea es ver qué pasa cuando hay un pico, qué tanto le cuesta al sistema recuperarse. Si hay un pico entonces ¿el sistema me queda colgado? ¿a los 10 segundos se recupera? ¿a las dos horas se recupera? ¿o qué? Para esto es necesario ya conocer cuál es el punto de quiebre del sistema, para poder preparar una prueba que esté por debajo de ese umbral, y generar un pico subiendo la carga por un período de un minuto por ejemplo, y luego bajarla.
El enfoque incremental que se puede aplicar aquí es en el pico en sí. Se podría comenzar experimentando con picos pequeños (de corta duración o poca carga) y luego estudiar cómo reacciona el sistema ante picos mayores. En cualquier caso, esto es algo que se debe modelar en base a un estudio de los comportamientos de los usuarios, especialmente en base a los access logs que se posean.
Conclusión
Cómo ejecutar las pruebas varía según el tipo de prueba, según la pregunta a la que queremos encontrar respuesta, pero tienen un aspecto en común: queremos reducir la cantidad de pruebas que ejecutamos, optimizando el costo y beneficio del testing. Para esto lo ideal es seguir un enfoque iterativo incremental (para pruebas de carga, endurance y picos) y de refinamiento (para estrés).
Por último, tener en cuenta también que estos tests se deben repetir con liberaciones de nuevas versiones para evitar que se introduzcan “errores” o cambios que degraden la performance. O sea, así como se ejecutan tests de regresión, también considerar performance dentro de esas regresiones. (Gracias a Ale Berardinelli por el aporte!)
Cualquier comentario será bien recibido, me encantaría saber cómo hacen esto en otros lados.
Además, si necesitas ayuda para definir tu plan de pruebas de performance, no dudes en contactarme.


Muchas gracias por el post, muy interesante.
Por favor su ayuda con la siguiente consulta: que tipo de aplicaciones no requieren pruebas de performance
Hola René,
es un tema de costo/beneficio, y de riesgos. Se me ocurre que puede existir cierto contexto en el cual uno asume el riesgo a tener problemas de performance, y se arriesga a poner en producción sin probar. Para esto es necesario medir el impacto que tendría tener problemas de performance en producción. Hoy en día con las exigencias de calidad que solemos tener, no lo veo muy aplicable a muchos contextos. De una forma u otra deberíamos mitigar un poco ese riesgo, y me atrevo a decir que la mayoría de las veces sería con pruebas de performance.
Espero que aporte mi comentario!
Hola Federico, excelente post!
Te consulto ya que necesito informacion sobre pruebas de performance sobre SAP HANA
He leido varios articulos donde mencionan herramientas pero necesito saber si existe alguna opcion open source. Serviria JMeter?
Muchas gracias
Hola!
No he tenido experiencia, pero estoy preguntando a ver si existe algún plugin en JMeter que puedas usar. Si averiguo algo te paso
Hola Federico, buen día. No tengo experiencia armando planes de pruebas de performance. Tu articulo me parece bastante enriquecedor y me dado un poco mas de luz, sin embargo, aún no sé como crear un plan de pruebas optimo. Tengo varias dudas. Tendrás algunas lecturas que me inicien en el armado de planes de pruebas o algún curso? De antemano te agradezco la atención.
Hola Daniel,
Creo que este artículo y sus referencias te pueden ayudar http://federico-toledo.com/pruebas-de-performance/