En este post quiero compartir un resumen de la charla que tuvo lugar en el evento de TestingUY edición 2017, la cual se tituó “Testing de performance: los nuevos desafíos tecnológicos”. En esta charla Leti y Pablo (de Abstracta) contaron sobre 4 temas bien importantes alrededor del testing de performance de hoy en día: pruebas en Cloud, uso de CDNs, CI/CD y HTTP2. Te dejo acá el resumen que ellos mismos prepararon:

El objetivo de esta charla fue presentarle a la comunidad cómo las nuevas tecnologías y desafíos tecnológicos de hoy en día infieren en el modo en que solíamos hacer las pruebas de performance. Para entrar en tema se comenzó planteando la pregunta ¿por qué les llamamos nuevos desafíos tecnológicos? En los últimos años como testers de performance hemos vivido grandes cambios que nos han llevado a usar otras herramientas y metodologías que se ajusten mejor a las necesidades de nuestros clientes. Quisimos con esta charla compartir cómo hizo nuestro equipo de performance para afrontar estos desafíos.
Hoy los clientes nos buscan con nuevas necesidades y nuevos requerimientos, y quisimos contarles cómo nosotros vemos que estos nuevos enfoques influyen en la manera en que hacemos las pruebas de performance y quizá a quién lea este artículo le pase algo similar, para lo cual queremos dejar abierto el espacio al intercambio por si alguien más se ha enfrentado con situaciones similares.
Claramente este cambio no fue un proceso que se dio solo, sino que los hemos aprendido trabajando codo a codo con empresas tanto locales como con empresas de Silicon Valley como BlazeMeter, Shutterfly, Mulesoft, Heartflow y colaborando con la comunidad de testers de performance, como lo son la comunidad de JMeter, herramienta para pruebas de performance opensource más usada y conocida por los testers de performance.
Encontramos interesante entonces organizar la charla en 4 temas o “pilares”:
Empecemos entonces a profundizar en cada uno de estos temas.
Pruebas de Performance en Cloud
Yo creo que si a priori no conocemos el concepto de Cloud, nos la podemos imaginar como una nube de servidores y máquinas. Por esto es que me encanta esta imagen la cual compartimos con el público:

Artwork By Chris Watterston-Independent designer.
Cloud no es más que un set de computadoras/servidores de alguien más. La gran ventaja que tiene es que esos servidores pueden estar distribuidos en cualquier parte del mundo y nos quita a nosotros la limitante de contar con infraestructuras físicas para alojar nuestros sistemas, o de tener que alojar nuestro sistemas lejos (geográficamente) de nuestros usuarios.
Además del alojamiento y distribución geográfica, la otra gran ventaja de trabajar con tecnologías en la nube es que pagamos por lo que usamos y no más. Por lo que Cloud termina siendo una alternativa fácil de usar/administrar y económica.
Dicho esto, entonces ¿cómo vemos que este enfoque infiere en el modo en el que solíamos hacer las pruebas de performance? La respuesta es: en la monitorización. La manera en que nosotros solíamos monitorizar, yendo a clientes, instalando agentes en los servidores físicos y recolectando indicadores ahora cambia. Esto dio lugar a la necesidad de nuevas tecnologías más adaptadas a estos esquemas de monitorización como Cloudwatch, New Relic entre otras. Pero no solo cambia en lo que tiene que ver con el alojamiento de los sistemas y la monitorización.
Hoy por hoy existe una gran oferta de sitios, como por ejemplo de e-commerce, que tienen miles de ingresos diarios, de usuarios de todas partes del mundo. De alguna manera nosotros como testers de performance tenemos que poder brindarle a esos sitios pruebas que simulen esta demanda de usuarios.
Antiguamente utilizábamos generadoras de carga como JMeter, pero teníamos el problema de que para simular miles de usuarios teníamos que levantar dos, tres, o más generadoras de carga, teniendo que configurar lo que conocemos como granja o clúster de servidores de prueba. Es por esto que el concepto de Cloud también nos ayuda dando lugar a herramientas en la nube como BlazeMeter que nos soluciona esta limitante, uno solo indica el script, el escenario de prueba y desde que parte del mundo queremos generar la carga y el software se encarga de levantar y configurar cuántas máquinas virtuales se necesiten para poder realizar la prueba.
Actualmente tenemos un partnership con BlazeMeter por lo que en conjunto estamos trabajando en mejorar las opciones que tenemos hoy en día para simular más fielmente las acciones de usuarios.
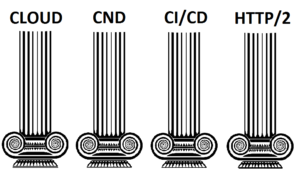
Para cerrar con este primer pilar, se compartió una experiencia de un proyecto en el que el enfoque Cloud jugó un rol importante. Este proyecto fue para una empresa del área de la salud de Estados Unidos. Esta empresa llegó a nosotros con la necesidad de probar la performance de su sistema. Ellos tenían toda su infraestructura alojada en Amazon con políticas de autoscaling y querían tener la posibilidad de simular carga desde distintas partes del mundo. Para esto usamos BlazeMeter. Gracias a estas pruebas nos dimos cuenta que la configuración que ellos tenían de autoscaling estaba haciendo que cada vez que un servidor alcanzaba un pico del 60% de uso de CPU se levantara un nuevo servidor.
Esto hace que se desperdicien recursos, ya que no se estaba comportando elásticamente, o sea, las máquinas creadas no se bajaban luego, sino que quedaban “encendidas” a pesar que no hacían falta. Al observar esto se realizó el cambio de las políticas de autoscaling y logramos reducir significativamente la cantidad de servidores que ellos necesitaban levantar reduciendo significativamente el dinero invertido en infraestructura. Gracias a las pruebas de performance realizadas, se evidenció un simple error de configuración que hubiera costado muy caro, tanto en dinero como en recursos a nuestro cliente.
CDN (Content Delivery Network)
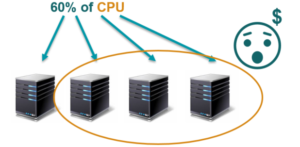
¿Qué entendemos por CDN? Podemos ver al CDN como un contenedor de recursos estáticos, distribuido geográficamente, dicho de otro modo, podemos ver los CDN como un caché distribuido por el mundo. Para entender un poco mejor de qué se trata un CDN analicemos cómo funciona. Supongamos que tenemos una aplicación alojada en Estados Unidos y un usuario queriendo acceder a ella desde Uruguay, tal como mostramos a continuación:
Entonces:
- El usuario solicita un recurso a la aplicación.
- El CDN lo recibe (los CDN tienen un DNS). Como es la primera vez que se realiza la solicitud, el CDN lo solicita al servidor de la aplicación.
- El servidor de aplicación se lo retorna al CDN.
- El CDN lo cachea en un servidor geográficamente cercano a la ubicación del solicitante (nuestro usuario).
- Luego el CDN se lo retorna a mi usuario.
- Lo interesante de esta tecnología es que si el mismo u otro usuario geográficamente cercano a mi primer usuario solicita el mismo recurso nuevamente, el CDN ya no tiene que ir hasta el servidor de aplicación a buscar el recurso.
- Directamente retorna el que acaba de guardar.
Cuando hablamos de recurso o solicitud, nos referimos a recursos estáticos como imágenes, JavaScript, CSS, etc. Es importante notar lo rápido que se vuelve la devolución del recurso, si la solicitud no tiene que llegar al servidor de aplicación y me lo devuelve directamente un servidor cercano al usuario.
Los CDNs tienen además como ventaja el manejo de seguridad, uno puede fácilmente habilitar el protocolo HTTPS y eso internamente habilita el uso de HTTP/2, tema que veremos más adelante en este artículo, así como sus ventajas. Para ver cómo configurar un CDN, por ejemplo Cloudflare, les dejo este post donde contamos lo fácil que es agregarlo a un sitio web.
Entonces, ¿cómo el uso de CDN nos cambia el modo en el que hacemos las pruebas de performance? Con los CDNs tenemos que ser más cuidadosos en cómo y de dónde recibimos los pedidos estáticos. Los clientes que utilizan CDN, como parte de sus pruebas, quieren verificar que sus CDNs estén redirigiendo los contenidos estáticos de manera correcta y es allí donde nuestro conocimiento sobre este enfoque debe serles de valor.
CI/CD (Continuous Integration/Continuous Deployment)
Creo que en mayor o menor medida todos hemos oído hablar sobre CI/CD. Pero, ¿a qué nos referimos cuando hablamos de CI/CD? Refiere a tener más instancias de deployment en el ciclo de desarrollo en la vida de un proyecto, tener el proceso de deploy tan automatizado que lo podemos hacer de manera más frecuente y con menor riesgo.
¿Qué ganamos haciendo deploy más frecuente? Ser capaces de detectar más temprano los errores, lo más cercano posible al momento en que se se insertó esa linea de código, esa configuración o ese cambio en el hardware que perjudica la salud de nuestro sistema.
Veamos cómo es el ciclo de vida de nuestro proyecto si aplicamos CI/CD, comenzando desde que el alguien del equipo de desarrollo envía código al repositorio:
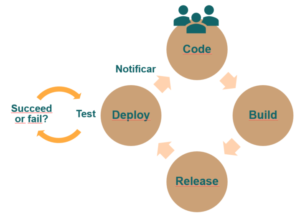
Es importante destacar que cuando se genera el deploy, automáticamente se desata una serie de pruebas que verificarán el éxito o no de nuestro build o deploy. Esas pruebas pueden ser pruebas unitarias, pruebas funcionales, revisión/chequeo estático de código y muchas más.
Lo interesante de este enfoque es que todo se hace de manera automática, y obtendremos una notificación si esas pruebas pasaron o no. Un ejemplo de una herramienta que da soporte a este tipo de automatismos es Jenkins.
Ahora, ¿cómo afecta esto a nuestras pruebas de performance? En el momento que se ejecuta el ciclo de pruebas de aceptación de nuestro deploy podemos sumar un set de pruebas unitarias de performance, para que también se detecten las degradaciones de performance lo antes posible. Existen herramientas más apropiadas para este enfoque tales como Gatling o Taurus.
En nuestras pruebas automatizadas habrán chequeos de performance, por ejemplo midiendo tiempos de respuesta de un servicio comparando contra un Baseline. De esta manera podemos tener una trazabilidad de las mejoras/o no, a nivel de performance, que se van dando en cada deploy.
Compartimos además la experiencia que tuvimos trabajando en esto para Shutterfly. Lo interesante de su contexto es que procesan grandes volúmenes de información diariamente, más de 6 millones de órdenes al año.
En el caso de ellos utilizaban Gatling como generadora de carga y Jenkins como motor de Integración Continua. Fue realmente asombroso, novedoso y alentador encontrar que las pruebas de performance jugaron un rol importante en su proceso de desarrollo, ayudando a mejorar la calidad final de su producto.
De este proyecto sacamos muchas experiencias, pero entre ellas la importancia de hacer un diseño de pruebas simple y mantenible que se ajusten a este enfoque. Si te resulta de interés esta experiencia podés leer lo que escribimos en el blog de Abstracta al respecto o escuchar el Webinar que hicimos junto a Melissa Chawla, la líder del equipo de performance de Shutterfly.
HTTP/2
Arrancamos este tema, preguntando ¿por qué HTTP/2? ¿ Por qué un nuevo protocolo? HTTP/1 se diseñó en 1996 (20 años atrás) e internet era muy distinto a lo que es hoy en día. Las páginas web estaban compuestas sólo por texto y alguna que otra imagen. Hoy por hoy internet está orientado a ofrecer aplicaciones web en donde tenemos mucho contenido multimedia y donde hay interacción constante con el usuario. Una página web puede tener cientos de recursos y HTTP/1 recomienda solo abrir dos conexiones TCP a la vez por dominio (los browsers no cumplen esta recomendación y abren hasta seis). Entonces, si necesitamos cargar una página web que tiene 100 recursos (algo normal hoy en día) a un mismo dominio, se tendrían que pedir de a dos recursos, esperar la respuesta, llega la respuesta y después recién puedo mandar dos pedidos más, etc., hasta completar los 100 recursos que necesito. La comunicación así es muy ineficiente.
Para mejorar la velocidad de internet, HTTP/1 cuenta con buenas prácticas. Estas buenas prácticas son indicadores que el protocolo HTTP/1 es ineficiente y que necesitamos un nuevo protocolo para cumplir con las exigencias de los usuarios actuales.
Todos conocen esas historias de empresas como por ejemplo Amazon que por cada segundo que demoran en ofrecer el contenido, pueden perder hasta 1.600 millones de dólares. También, hay estudios que descubrieron que el 57 % de los usuarios abandona un sitio si este no carga en menos de 3 segundos. En definitiva a nadie le gusta esperar. Queremos contenido y lo queremos de manera instantánea. Entonces, HTTP/2 llega para mejorar la performance de nuestras aplicaciones web y la experiencia de usuario.
HTTP/2 surge de un experimento de Google en 2009, SPDY. Se juntaron desarrolladores de Google con el fin de mejorar la velocidad y seguridad de internet. Este protocolo es binario, no es orientado al texto como lo es HTTP/1 lo que desemboca en una mejora en la rapidez y facilidad en el parseo de las respuestas de un servidor.
En este protocolo además se comprime el header que conocemos hoy en día. En HTTP/1 se envía mucha información redundante en los headers, por lo que HTTP/2 elimina esta información redundante (la envía una sola vez) y además utiliza un algoritmo de comprensión sobre el header.
A su vez, el protocolo HTTP/2 está implementado sobre HTTPS. Todos los browser usan TLS sobre HTTP/2 y esto mejora la seguridad de nuestras aplicaciones web.
Otra característica importante es la de multiplexing. Como se dijo HTTP/1 recomienda dos conexiones TCP por dominio. Actualmente los browser rompen esta regla y abren hasta seis conexiones TCP con un mismo dominio. Como se ve en la figura si quiero tres recursos tengo que abrir tres conexiones TCP distintas.
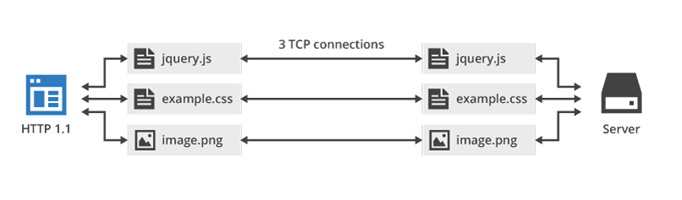
El protocolo HTTP/2, en cambio, abre una sola conexión TCP para pedir los tres recursos y esto se denomina Multiplexing.
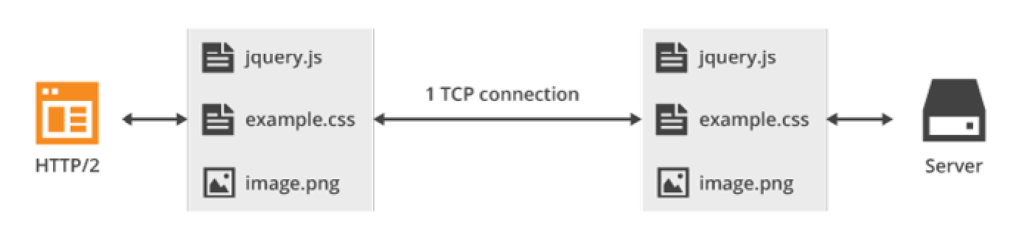
Es decir, HTTP/2 permite mandar varios requests en paralelo y la respuesta del servidor también es en paralelo sin importar el orden en el que se recibe esas respuestas. Esto evita las esperas que tiene HTTP/1 a causa de la secuencialidad.
Otro gran avance de HTTP/2 es el Server Push, el cual permite acceder a los pedidos secundarios de manera mucho más sencilla. En HTTP cuando solicitamos una página web primero se solicita el HTML y luego que lo recibimos, se parsea dicho archivo y se obtienen todos los recursos comenzando luego a enviar dichos pedidos de a dos o de a seis como hacen los browsers. Con HTTP/2, el servidor es más proactivo y cuando pedimos el HTML, además de enviarnos el archivo HTML también nos envía los pedidos estáticos que él cree que vamos a necesitar luego de parseando el HTML.
Server Push tiene que ser utilizado con cuidado porque podríamos sobrecargar la red enviando muchos recursos que quizás ya tenemos guardados en el cache del browser. No necesariamente nos tiene que devolver todos los recursos secundarios sino aquellos más importantes que nos den la sensación de que la pagina se cargó rápido. Por ejemplo puede ser la imagen del cabezal de la página.
Por esto es que se dice que HTTP/2 acelera Internet. Pero nuevamente, ¿qué consideraciones tengo que tener como tester de performance al realizar mis pruebas?
Pensando primero que nada en la automatización de pruebas, hoy en día para capturar el tráfico HTTP/2 contamos solo con WireShark o Net internals de Google Chrome.
Respecto a los generadores de carga, ¿cómo podemos simular pedidos HTTP/2? Para esto contamos con herramientas licenciadas como LoadRunner, que por el momento, si bien soporta HTTP/2 no soporta Server Push.
Aún no tenemos herramientas gratuitas que den soporte a este nuevo protocolo, por lo que no podemos en la actualidad simular fielmente acciones de usuarios sobre sitios que soportan HTTP/2. Sin embargo, nuestro equipo viene trabajando codo a codo con BlazeMeter en el desarrollo de un plugin para poder soportar HTTP2 en JMeter. En el desarrollo de este plugin nos hemos enfrentado a grandes dificultades como la de procesar las respuestas de manera asincrónica adaptando el modelo sincrónico de JMeter a un modelo asincrónico. Además estamos trabajando en el desarrollo de plugins de JMeter que den soporte a HLS y WebSocket que cada vez son más utilizados. Se enterarán cuando esos plugins queden disponibles, ya que serán opensource.
Resumiendo
En la charla vimos cómo estos enfoques infieren en la manera que hacemos las pruebas de performance.
- CLOUD: Cambiamos el modo en que monitorizamos y generamos carga distribuida geográficamente. Pagamos por lo que usamos.
- CDN: Tenemos que analizar desde dónde y cómo nos llegan los recursos estáticos.
- CI/CD: Tenemos que adaptar nuestros scripts de performance de modo de integrarlos en un ambiente de Integración Contínua para obtener resultados inmediatos.
- HTTP/2: Necesitamos contar con herramientas gratuitas que den soporte a los nuevos protocolos que utilizan hoy en día las aplicaciones de los usuarios.
Pero además de esto, lo que quisimos transmitir con nuestra charla es que si bien mencionamos grandes empresas como HeartFlow, Shutterfly o BlazeMeter, queremos inspirar a nuestra comunidad, clientes y colegas a adoptar estos nuevos enfoques. Esto les permitirá llevar sus pruebas de performance al siguiente nivel, cumpliendo así con las exigencias de hoy en día y seguir el camino que está siguiendo nuestra industria.
Desde ya los invitamos a compartir sus experiencias con nosotros, ¿con qué desafíos tecnológicos te has enfrentado como tester de performance?
Enlace de la presentación: https://www.slideshare.net/lalmeidaAbs/testing-de-performance-los-nuevos-desafos-tecnolgicos
Video de la charla:
Charla en #testinguy: Testing de performance by @lalmeida88 & Pablo
¡Te esperamos!
Inscripción 16/5 día charlas: https://t.co/pCUYqzPbe0 pic.twitter.com/bzMmAMYaWy— TestingUy (@testingUY) May 8, 2017




3 thoughts on “Testing de Performance: Los nuevos desafíos tecnológicos (charla de Abstracta en TestingUY 2017)”