Dado que tenía que actualizar el post en el antiguo blog de Abstracta (que escribí en 2016), decidí pasarlo para acá. Este es el tercer y último paso del tutorial de Gatling. En este veremos ejecución de pruebas y reportes.
Uno de los aspectos interesantes de esta herramienta está en los buenos reportes que nos brinda luego de ejecutar las pruebas. Ya estuvimos viendo un resumen de la herramienta, cómo grabar scripts y cómo editarlos. Ahora la parte más entretenida, la ejecución de pruebas y reportes.
Para ejecutar el script que preparamos con Gatling, simplemente se ejecuta /gatling.bat. Primero nos preguntará qué archivo queremos ejecutar, y luego nos dará la posibilidad de ingresar un identificador y una descripción para la prueba. Cuando comienza a ejecutar nos muestra una pantalla como la siguiente, donde resume las principales métricas obtenidas hasta el momento:
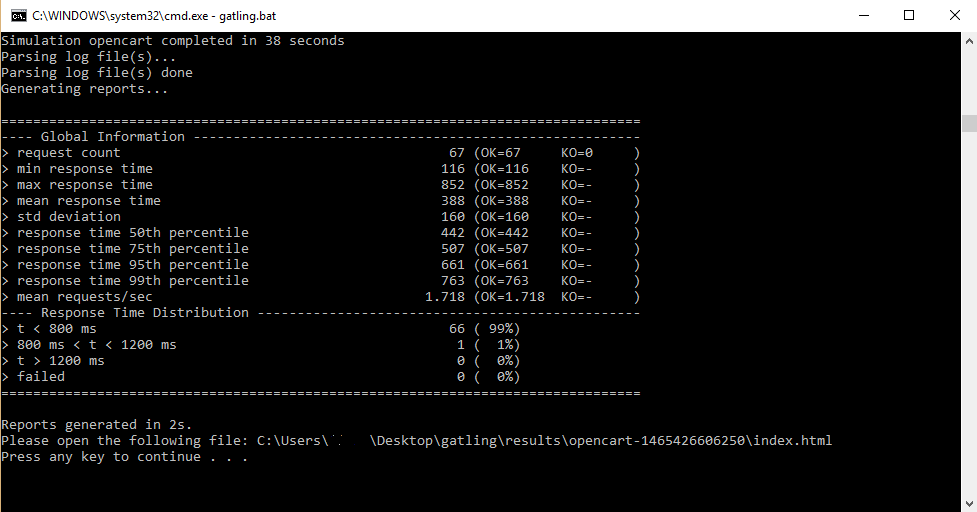
Al finalizar nos indica dónde nos deja el reporte HTML.
Reportes en HTML
El reporte que muestra como resultado al final de la prueba es realmente muy bueno. Es colorido, prolijo, con mucha información bien presentada y fácil de navegar.
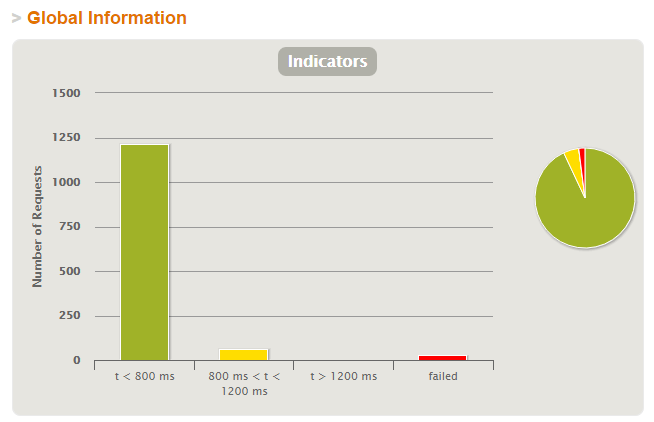
En primera instancia muestra un resultado bien fácil de entender de cómo resultó la prueba, en cuanto a respuestas fallidas, y en cuanto a distribución de los tiempos de respuesta:
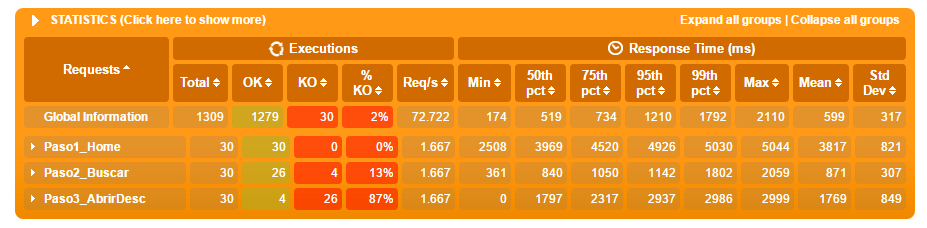
Luego muestra la estadística completa de todas las peticiones realizadas, tanto las primarias como los recursos embebidos, mostrando los que fallaron y los que pasaron las validaciones, así como un desglose de los tiempos de respuesta considerando no solo promedio, sino que también los distintos percentiles:
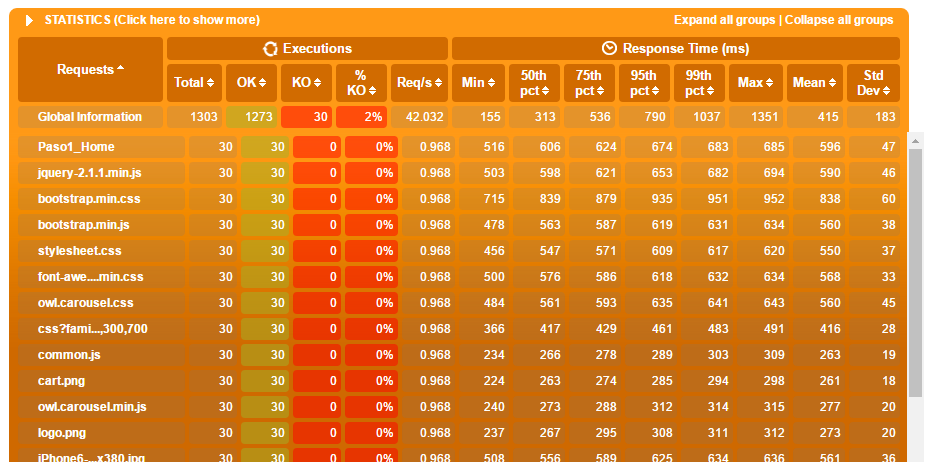
Si querés recordar qué son los percentiles y su importancia, leé acá.
Se muestra un resumen de los errores encontrados:

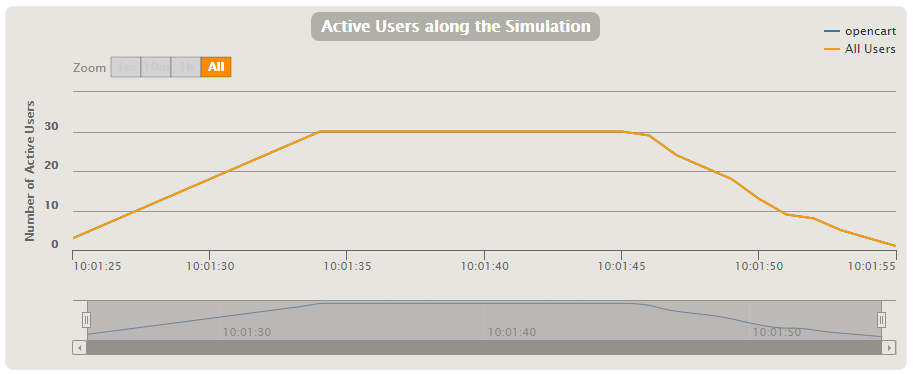
Cantidad de usuarios activos durante la prueba:
Los tiempos de respuesta obtenidos durante la prueba:
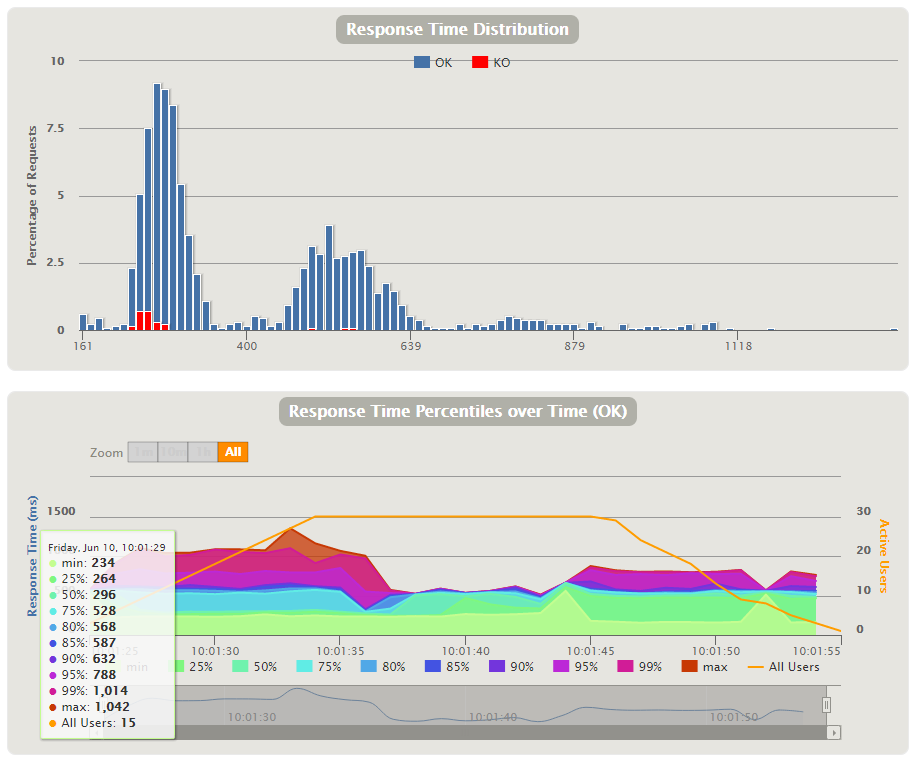
Encuentro muy útil que en la primera se combinen los tiempos de respuesta, así como los requests que fallaron. En la segunda muestra un detalle de los tiempos en cuanto a los percentiles, pudiendo ver dónde se concentraron la mayoría de los tiempos de respuesta en cada intervalo.
Una novedad para mí, es que además de mostrar los requests/segundo también muestra los responses/segundo.
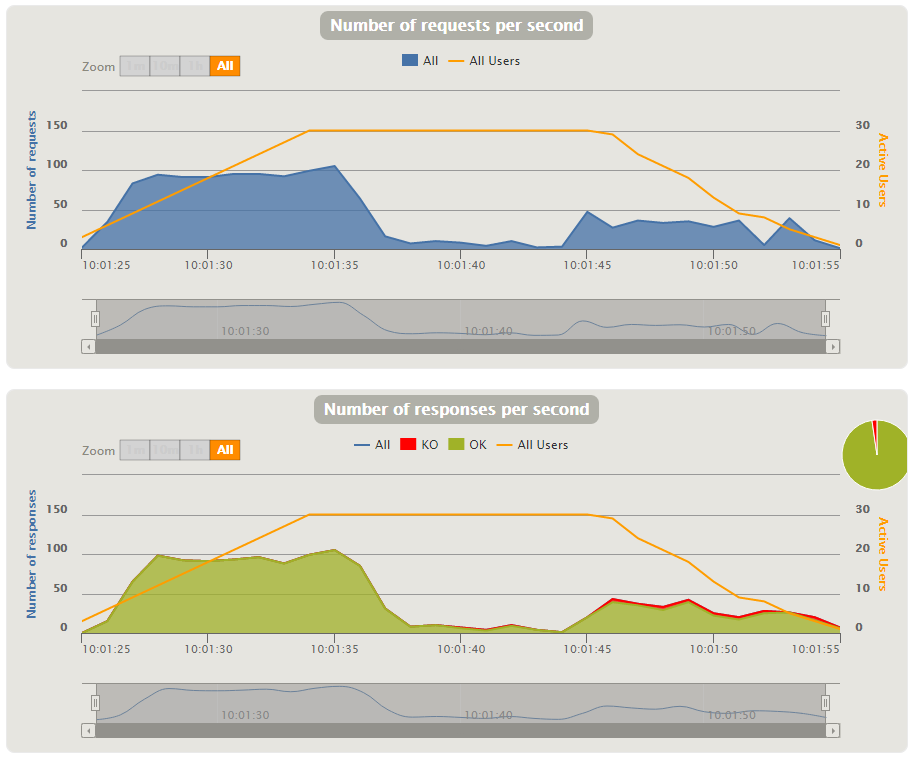
Es interesante observar que con la barra gris que está debajo de cada gráfico se puede hacer zoom en ellos para focalizar y analizar en detalle en determinados puntos de la prueba. En estas gráficas también es interesante ver cómo cruza la información de transacciones por segundo con la cantidad de usuarios activos durante la prueba.
Algo que también está bien útil es definir grupos, de forma de poder agrupar y sumarizar los tiempos de distintos requests. Así, dentro del grupo quedan anidados todos los pedidos relacionados. Esto nos lleva a una buena práctica de definir un grupo para cada paso, a pesar que tenga un solo request, ya que de esta forma vamos a poder tener los tiempos de respuesta de toda una página, incluyendo sus recursos embebidos.
Entonces, si cambiamos el script y lo reestructuramos de esta forma:

Obtendremos un reporte mucho más fácil de navegar aún:
Donde cada uno de los pasos se puede ampliar y ver el detalle por cada request.
Toda esta información se puede ver en detalle para cada “request” como para refinar el análisis yendo a la pestaña “Details” en la parte superior del reporte.
Lo único que veo que le estaría faltando, que es bastante común en otras herramientas, es el resumen de los datos transferidos durante la prueba. Esto igual se puede obtener fácilmente con monitorización a nivel de red en la generadora de carga.
Otra limitante muy grande es que el reporte lo puedo ver al finalizar la prueba. Durante la ejecución no hay forma simple de ir viendo cómo va.
Performance de la herramienta
Parece chiste, pero es muy importante conocer cuál es la performance de la herramienta, para poder determinar cuántos usuarios concurrentes se pueden ejecutar por máquina. En la página del producto dice que gracias a que usan un mecanismo asincrónico no bloqueante, la herramienta tiene un alto rendimiento. Hicimos un benchmark entre Gatling y JMeter que compartimos acá.
Por otra parte, una estrategia muy utilizada en estas herramientas para poder escalar la cantidad de carga generada es la de distribuir el trabajo entre distintas máquinas, siguiendo un esquema maestro-esclavo. O sea, se distribuyen los usuarios virtuales a generar entre distintas máquinas, donde hay una que centraliza la coordinación y gestión, así como los resultados. La limitación más grande en este sentido es que no escala horizontalmente. O sea, no tiene la posibilidad de distribuir la carga entre varias máquinas.
En la documentación muestran un mecanismo para poder escalar que también me queda pendiente probar. Lo pueden ver aquí, donde básicamente plantean armar un script para invocar de manera remota y coordinada la prueba en cada máquina, y luego un truco para poder centralizar los distintos reportes en uno solo.
Por último, se puede escalar utilizando la nube de Flood.io o BlazeMeter (usando Taurus).